
124
Visualizações

Última atualização em

Um dos maiores erros dos proprietários de novos sites não é procurar o arquivo robots.txt. Então, o que é assim mesmo e por que é tão importante? Nós temos suas respostas.
Se você possui um site e se preocupa com a saúde do SEO do seu site, familiarize-se com o arquivo robots.txt em seu domínio. Acredite ou não, esse é um número perturbadoramente alto de pessoas que iniciam um domínio rapidamente, instalam um site rápido do WordPress e nunca se incomodam em fazer nada com o arquivo robots.txt.
Isso é perigoso. Um arquivo robots.txt mal configurado pode realmente destruir a integridade do SEO do seu site e prejudicar as chances de você aumentar o tráfego.
o Robots.txt o nome do arquivo é apropriado porque é essencialmente um arquivo que lista diretivas para os robôs da Web (como robôs de mecanismo de pesquisa) sobre como e o que eles podem rastrear no seu site. Esse é um padrão da Web seguido pelos sites desde 1994 e todos os principais rastreadores da Web aderem ao padrão.
O arquivo é armazenado em formato de texto (com extensão .txt) na pasta raiz do seu site. Na verdade, você pode visualizar o arquivo robot.txt de qualquer site digitando o domínio seguido por /robots.txt. Se você tentar fazer isso com o groovyPost, verá um exemplo de um arquivo robot.txt bem estruturado.
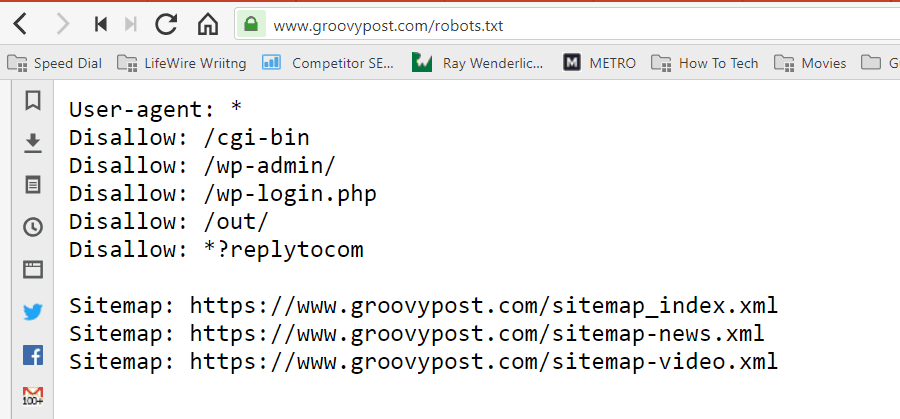
O arquivo é simples, mas eficaz. Este arquivo de exemplo não diferencia entre robôs. Os comandos são emitidos para todos os robôs usando o comando Agente de usuário: * directiva. Isso significa que todos os comandos a seguir se aplicam a todos os robôs que visitam o site para rastrear.
Você também pode especificar regras específicas para rastreadores da web específicos. Por exemplo, você pode permitir que o Googlebot (rastreador da Web do Google) rastreie todos os artigos em seu site, mas convém proibir o rastreador da web russo Yandex Bot de rastrear artigos em seu site que tenham informações depreciativas sobre Rússia.
Existem centenas de rastreadores da Web que vasculham a Internet em busca de informações sobre sites, mas os 10 mais comuns com os quais você deve se preocupar estão listados aqui.
Tomando o exemplo de cenário acima, se você deseja permitir que o Googlebot indexe tudo no seu site, mas deseja Para impedir que o Yandex indexe o conteúdo do seu artigo em russo, adicione as seguintes linhas ao seu robots.txt Arquivo.
Agente do usuário: googlebot
Não permitir: Não permitir: / wp-admin /
Não permitir: /wp-login.php
Agente do usuário: yandexbot
Não permitir: Não permitir: / wp-admin /
Não permitir: /wp-login.php
Não permitir: / russia /
Como você pode ver, a primeira seção impede o Google de rastrear sua página de login e páginas administrativas do WordPress. A segunda seção bloqueia o Yandex da mesma, mas também de toda a área do seu site em que você publicou artigos com conteúdo anti-Rússia.
Este é um exemplo simples de como você pode usar o Proibir comando para controlar rastreadores da web específicos que visitam seu site.
Proibir não é o único comando ao qual você tem acesso no seu arquivo robots.txt. Você também pode usar qualquer um dos outros comandos que direcionarão como um robô pode rastrear seu site.
Tenha em mente que os bots serão só ouça os comandos que você forneceu ao especificar o nome do bot.
Um erro comum que as pessoas cometem é proibir áreas como / wp-admin / de todos os bots, mas depois especificar uma seção do googlebot e proibir apenas outras áreas (como / about /).
Como os robôs seguem apenas os comandos especificados na seção deles, é necessário reajustar todos os outros comandos especificados para todos os robôs (usando o * user-agent).
Lembre-se de que o robots.txt destina-se a ajudar robôs legítimos (como robôs de mecanismo de pesquisa) a rastrear seu site com mais eficiência.
Existem muitos rastreadores nefastos por aí que estão rastreando seu site para fazer coisas como raspar endereços de email ou roubar seu conteúdo. Se você quiser tentar usar seu arquivo robots.txt para impedir que esses rastreadores rastreiem qualquer coisa em seu site, não se preocupe. Os criadores desses rastreadores geralmente ignoram tudo o que você colocou no seu arquivo robots.txt.
Conseguir que o mecanismo de pesquisa do Google rastreie o máximo de conteúdo de qualidade possível em seu site é uma preocupação principal para a maioria dos proprietários de sites.
No entanto, o Google gasta apenas um tempo limitado orçamento de rastreamento e taxa de rastreamento em sites individuais. A taxa de rastreamento é quantas solicitações por segundo o Googlebot fará no seu site durante o evento de rastreamento.
Mais importante é o orçamento de rastreamento, que é o número total de solicitações que o Googlebot fará para rastrear seu site em uma sessão. O Google gasta seu orçamento de rastreamento concentrando-se em áreas do seu site muito populares ou que foram alteradas recentemente.
Você não é cego para essas informações. Se você visitar Ferramentas do Google para webmasters, você pode ver como o rastreador está lidando com seu site.
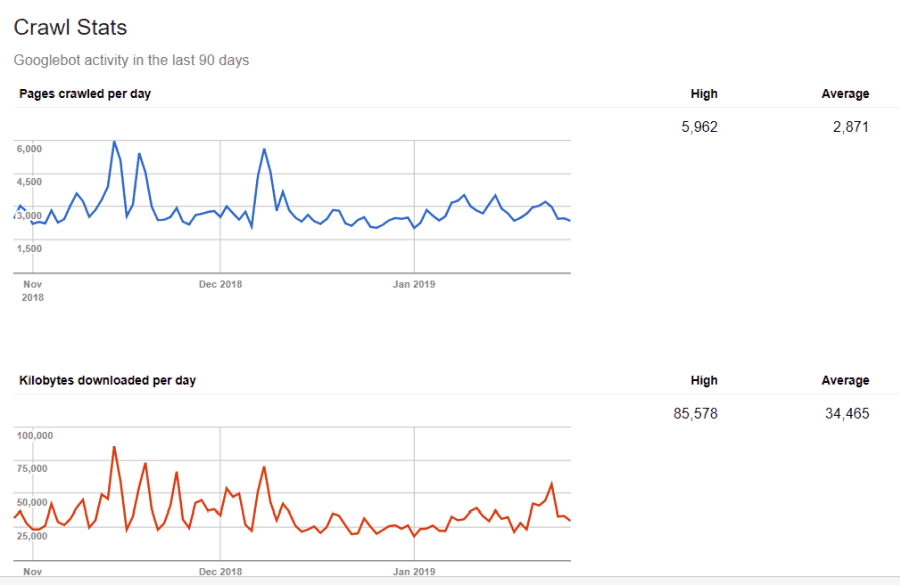
Como você pode ver, o rastreador mantém a atividade no seu site bastante constante todos os dias. Ele não rastreia todos os sites, mas apenas os que considera mais importantes.
Por que deixar para o Googlebot decidir o que é importante em seu site, quando você pode usar seu arquivo robots.txt para dizer quais são as páginas mais importantes? Isso impedirá que o Googlebot perca tempo em páginas de baixo valor em seu site.
As Ferramentas do Google para webmasters também permitem verificar se o Googlebot está lendo bem o seu arquivo robots.txt e se há algum erro.
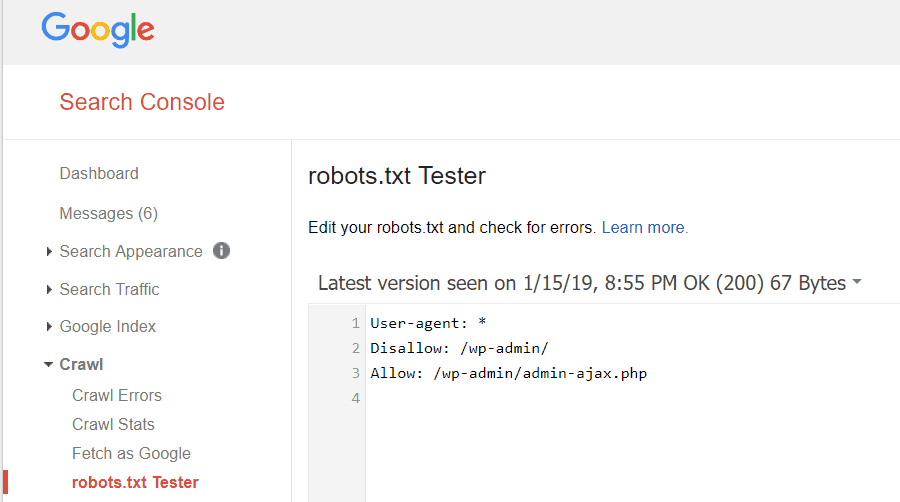
Isso ajuda a verificar se você estruturou seu arquivo robots.txt corretamente.
Quais páginas você deve proibir do Googlebot? É bom que o SEO do seu site proíba as seguintes categorias de páginas.
O maior erro que os novos proprietários de sites cometem é nunca olhar para o arquivo robots.txt. A pior situação pode ser que o arquivo robots.txt esteja realmente impedindo o rastreamento ou áreas do seu site.
Verifique seu arquivo robots.txt e verifique se ele está otimizado. Dessa forma, o Google e outros mecanismos de pesquisa importantes "veem" todas as coisas fabulosas que você oferece ao mundo em seu site.

