
0
Visualizações


Última atualização em

A Wayback Machine é a parte mais popular do Site do Internet Archive. Introduzida pela primeira vez em 2001, a ferramenta online gratuita permite que você “volte no tempo” para ver como eram os sites em todo o mundo em determinados momentos. O Wayback Machine apresenta 562 bilhão páginas da web no momento em que este artigo foi escrito, com muitas outras adicionadas a cada ano.
Aqui está uma olhada na Wayback Machine e o que a torna especial.
Criado por Brewster Kahle e Bruce Gilliat, o Internet Archive é uma organização sem fins lucrativos com a missão declarada de “acesso universal a todo o conhecimento”. Do começo, a organização forneceu acesso público gratuito a materiais digitalizados, como páginas da web, livros, gravações de áudio, incluindo shows ao vivo, vídeos, imagens e software programas.
Até o momento, tudo coletado pelo Internet Archive ocupa mais de 70 Petabytes de espaço no servidor, incluindo duas cópias de tudo. A organização é financiada por meio de doações, subsídios e taxas de serviços de digitalização de livros. Para privacidade, o Internet Archive não rastreia os endereços IP de seus leitores e usa o protocolo HTTPS (seguro) em todo o processo.
Apenas uma parte do Internet Archive, a Wayback Machine, foi projetada para capturar o conteúdo do site que foi alterado ou removido. Desde o lançamento, tornou-se um dos locais mais populares e reconhecidos da web. Kahle e Gilliat batizaram o site em homenagem ao dispositivo fictício de viagem no tempo da série animada dos anos 1960, The Rocky and Bullwinkle Show.
Embora o Internet Archive não tenha lançado o site ao público até outubro de 2001, a Wayback Machine começou a arquivar páginas da web em cache a partir de maio de 1996. Até 2001, as fitas digitais armazenavam informações acessíveis apenas a cientistas e pesquisadores selecionados. Quando tudo foi ao ar para o público cinco anos depois (como foi planejado há muito tempo), ele já continha mais de 10 bilhões de páginas arquivadas.
Hoje, o site mantém dados históricos da web em um cluster de nós Linux. A Wayback Machine baixa todas as informações publicamente acessíveis e arquivos de dados em páginas da web por meio de seu mecanismo de rastreamento. No entanto, nem tudo postado em um site está incluído aqui, já que parte do conteúdo é restrito ou armazenado em bancos de dados, que não são acessíveis. Por causa disso, alguns sites são rastreados melhor do que outros, dependendo de como os desenvolvedores criaram um site por vez.
Você também notará que quanto mais novo for o arquivo, mais conteúdo estará disponível para um determinado site. Uma nova ferramenta que o Internet Archive introduziu em 2005 é um dos motivos pelos quais os dados mais recentes são mais completos. O Archive-It.org ajuda a superar inconsistências em sites parcialmente armazenados em cache, permitindo que instituições e criadores de conteúdo colham e preservem coleções de conteúdo digital.
Os rastreadores da Web, às vezes chamados de spider ou spiderbot, são tão antigos quanto a própria Internet. Esses rastreadores são bots da Internet que navegam continuamente na web para fins de indexação, o que os torna um componente importante de qualquer mecanismo de pesquisa moderno. Os rastreadores usados pela Wayback Machine para criar instantâneos digitais de sites vêm de várias fontes, que mudaram com o tempo.
Como você notará rapidamente, a frequência de capturas instantâneas varia muito de acordo com o site. Normalmente, quanto maior (e talvez mais popular) um site, mais rastreamento ocorre. Além disso, muito depende da frequência com que um site muda de página. Mesmo os menores sites são eventualmente rastreados, a menos que haja uma razão para isso não acontecer. Por exemplo, sites protegidos por senha não são rastreados, nem os sites cujos proprietários solicitaram que eles não fossem incluídos.
O site da Wayback Machine é fácil de usar. Para encontrar instantâneos históricos de um site, digite seu nome no mecanismo de busca do site. Na página de resultados da pesquisa, os hiperlinks indicam as datas e horas em que um site foi arquivado. Clique no link para ver o site “de volta no tempo”.
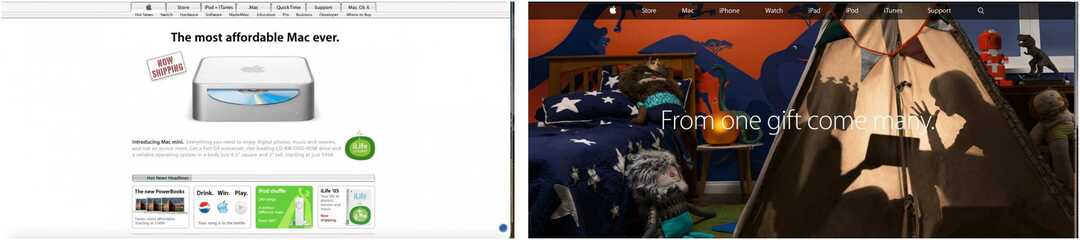
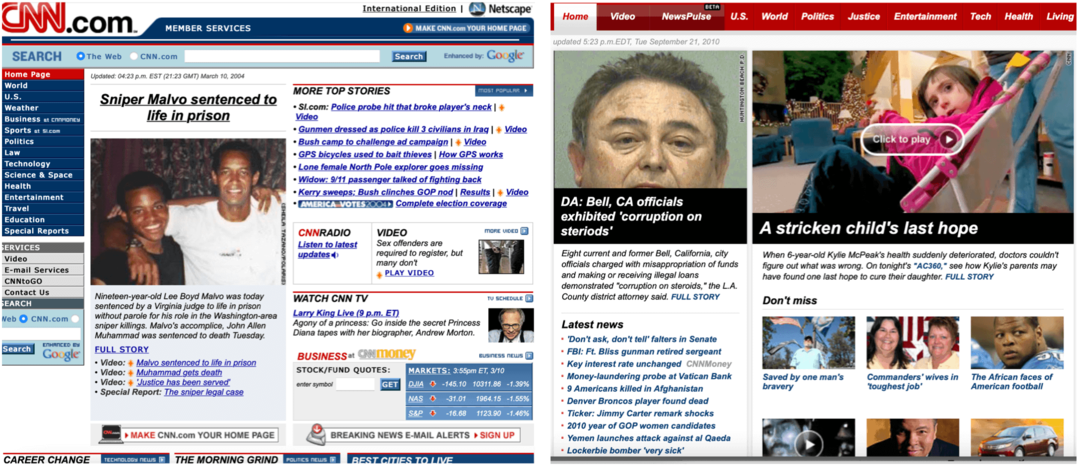
Nos exemplos a seguir, você pode ver a página inicial do site da Apple gravada em fevereiro de 2005 e novembro de 2014, e a página inicial da CNN a partir de março de 2004 e setembro de 2010.
Observação: esses rastreamentos também incluem links para outras páginas, conforme registrado nas datas especificadas, não apenas para as páginas iniciais.
Criado para pesquisadores e para o público, o Wayback Machine tem algumas ferramentas integradas que os usuários casuais podem perder. Por exemplo, por design, as páginas de resultados de pesquisa são fáceis de consultar. Conforme explicado, “Se você encontrar uma página arquivada que gostaria de consultar em sua página da Web ou em um artigo, pode copiar o URL. Você pode até usar correspondência de URL difusa e especificação de data... mas isso é um pouco mais avançado. ”
O Wayback Machine também permite que os proprietários de sites usem o recurso “Salvar página agora” para salvar uma página específica. E ainda assim, não é perfeito. Atualmente, o recurso não adiciona o URL do site a nenhum rastreamento futuro. Além disso, a solicitação não salva mais de uma página. No entanto, é um bom primeiro passo para arquivar a página inicial do seu site para o registro histórico.
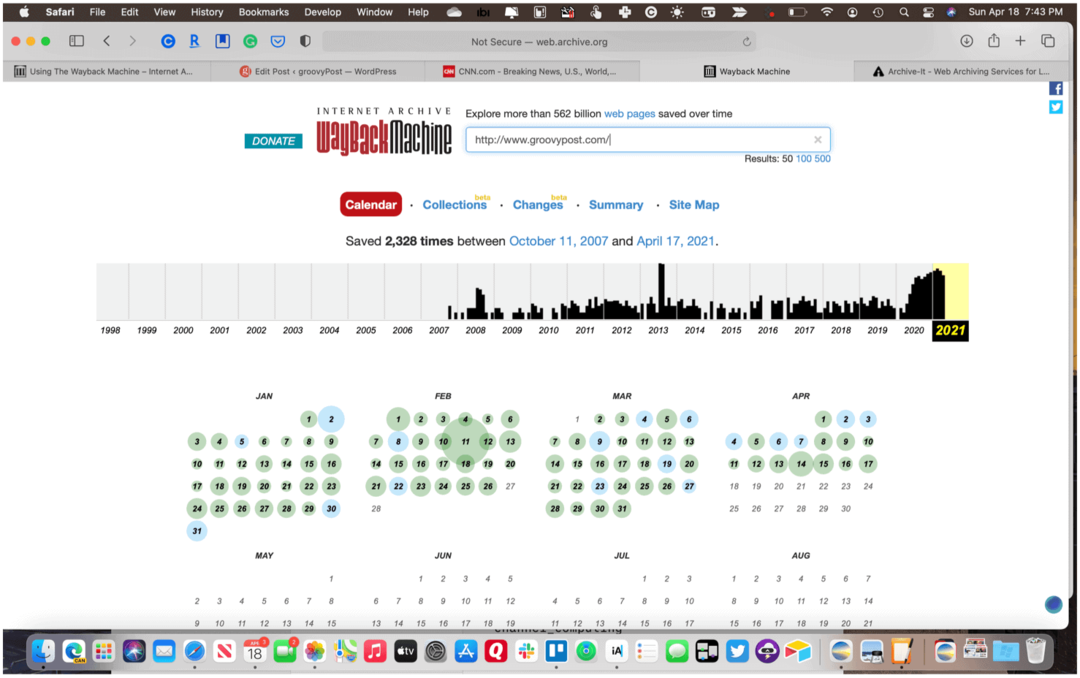
Você não precisa visitar a Wayback Machine todas as vezes para fazer uma nova pesquisa. Em vez disso, você pode encontrar conteúdo digitando o endereço na barra de ferramentas do navegador da web. Use este formato para todas as pesquisas: http://web.archive.org/*/www.yoursite.com/*. Por exemplo, use http://web.archive.org/*/www.groovypost.com/* para encontrar páginas arquivadas para o GroovyPost!
Finalmente, a Wayback Machine não está localizada apenas na web. Você pode encontrar um aplicativo Wayback Machine para iOS e Android. Também existem extensões para Chrome, Safari e Firefox. Os desenvolvedores também vão querer verificar as APIs do Internet Archive Wayback Machine. Isso torna mais fácil para os desenvolvedores recuperar informações sobre os dados de captura do Wayback.
O Internet Archive Wayback Machine oferece suporte a várias APIs diferentes. Ao fazer isso, torna-se mais fácil para os desenvolvedores recuperar informações sobre os dados de captura do Wayback.
Voltar “no tempo” para seus sites favoritos é o motivo número 1 para visitar a Wayback Machine. Também é uma ótima ferramenta para quem está pesquisando a história do site para projetos escolares ou para uso comercial. Faça o que fizer, visite a Wayback Machine e veja o que pode descobrir em alguns passos simples.
Para obter mais informações sobre o serviço de assinatura Archive-It do Internet Archive, visite o website oficial e comece a contribuir hoje!

